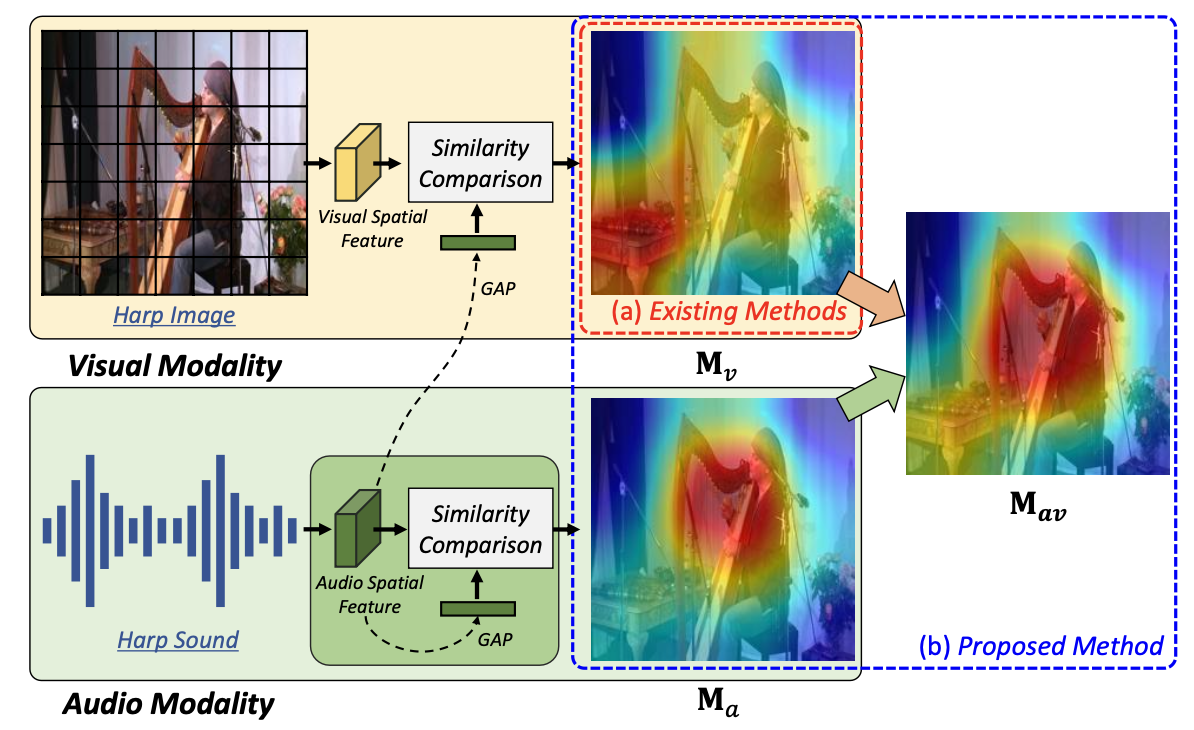
This work proposes a new approach for sound source localization that leverages both visual and audio spatial cues. Unlike conventional methods primarily using audio information as an auxiliary input, we integrate the spatial features of both modalities through an Audio-Visual Spatial Integration Network and refine the attention map iteratively via a Recursive Attention Network. This design mimics how humans utilize both visual and auditory clues to localize sound-making objects more precisely by repeatedly focusing on the relevant regions and discarding background noise.
By combining each modality’s attention map to form an audio-visual integrated feature, and then recursively refining it, the proposed method surpasses existing state-of-the-art approaches in unsupervised localization tasks on benchmark datasets such as Flickr-SoundNet and VGG-Sound Source. Furthermore, the model demonstrates robust performance even when applied to cross-dataset scenarios, indicating strong generalization capabilities.