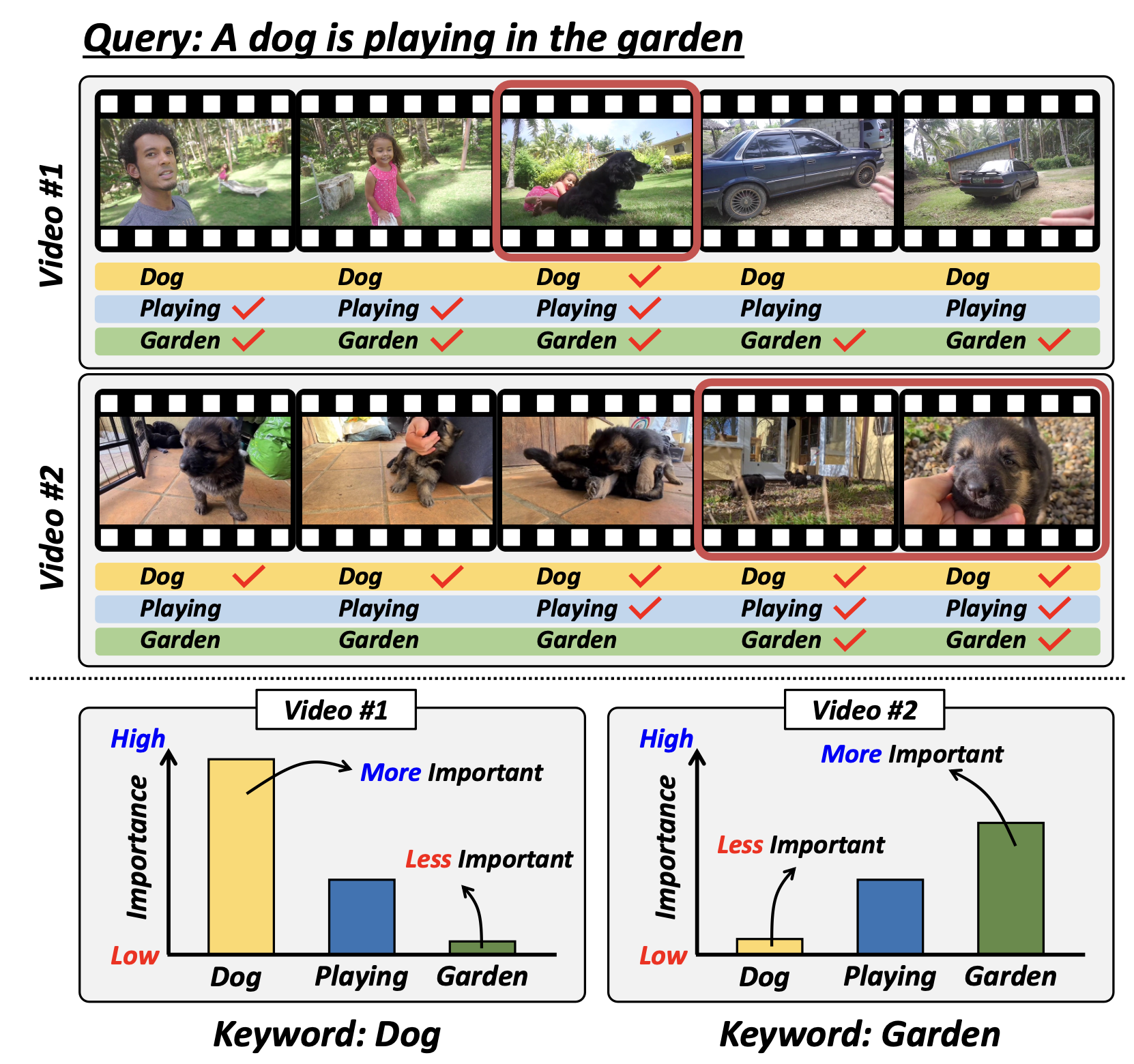
This work introduces a Context-aware Keyword Attention module for jointly solving moment retrieval and highlight detection in videos. Recognizing that the importance of words in a text query can shift depending on the overall video context, we first cluster similar video segments to capture high-level scene changes, and then measure how frequently each query term appears across these clusters. Less frequent yet contextually specific words receive higher attention, guiding the model to more accurately align text and video segments.
Our approach integrates this keyword-weighted text representation into a DETR-based framework, leveraging keyword-aware contrastive learning to refine both moment retrieval boundaries and highlight saliency scores. Experiments on various benchmarks (QVHighlights, TVSum, Charades-STA) demonstrate consistent improvements over existing methods, validating the importance of adapting keyword relevance to the actual content of each video.